SQL
选择数据
SELECT
选择表中的数据
SELECT col1 from mytable;
JOIN / LEFT JOIN / RIGHT JOIN & UNION
选择多张表中数据
SELECT table.col1, table.col2, table_else.col3 FROM
(SELECT col1, col2 FROM mytable) table
JOIN
(SELECT col1, col3 FROM mytable_else) table_else
ON
table.col1 = table_else.col1;
JOIN 类型
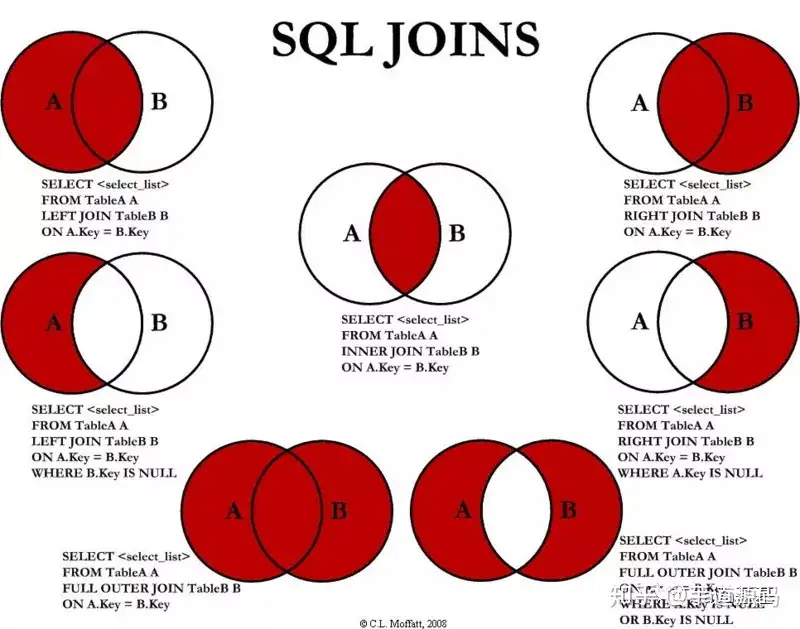 LEFT JOIN ON(左上)
RIGHT JOIN ON(右上)
JOIN / INNER JOIN ON(中)
FULL OUTER JOIN ON(左下)
LEFT JOIN ON(左上)
RIGHT JOIN ON(右上)
JOIN / INNER JOIN ON(中)
FULL OUTER JOIN ON(左下)
UNION & UNION ALL
列出所有在两个表的不同col1名
SELECT col1 FROM mytable
UNION
SELECT col1 FROM mytable_else;
列出所有在两个表的col1名
SELECT col1 FROM mytable
UNION ALL
SELECT col1 FROM mytable_else;
降维 聚筛去条字
常用函数
| 函数大类 | 函数小类 | 函数位置 | 举例 |
|—|—|—|—|
| 降维 | 聚合 | elements | COUNT
MAX
MIN
AVG
SUM
|
| 数据尺度 | 聚合 | conditions | GROUP BY |
| 数据尺度 | 筛选 | conditions | WHERE
LIMIT
|
| 数据尺度 | 排序 | conditions | ASC
DESC
ORDER BY |
| 数据尺度 | 去重 | elements | DISTINCT |
| 数据尺度 | 条件 | element | CASE WHEN |
| | 字符串 | | SUBSTR
CONCAT
SPLIT
|
聚合
COUNT / MAX / MIN / SUM
统计不同col1的个数 DISTINCT 对结果集去重,对全部选择字段进行去重,并不能针对其中部分字段进行去重。使用COUNT DISTINCT进行去重统计会将reducer数量强制限定为1,而影响效率,因此适合改写为子查询
SELECT COUNT(*) FROM
(SELECT DISTINCT col1 from mytable) table;
GROUP BY
统计不同col2的不同col1的个数
SELECT COUNT(DISTINCT col1) FROM mytable
GROUP BY col2;
统计col1的最大最小和平均值
SELECT MAX(col1), MIN(col1), AVG(col1) FROM mytable
GROUP BY col2;
GROUP BY与分组排序:row_number() OVER(patition by order by desc)
按照字段col1分组后按照col2倒序排列
SELECT *, row_number() OVER (patition by col1 order by col2 DESC) as col from mytable;
| 分组排序类型 | 特点 | 例子 |
|---|---|---|
| row_number() | 相同时不重复,根据顺序排序 | 1,2,3 |
| rank() | 排序相同时会重复,总数不变 | 1,1,3 |
| dense_rank() | 排序相同时会重复,总数减少 | 1,1,2 |
筛选
WHERE
统计col_4 为 A, 根据col2分组的col1个数
SELECT COUNT(DISTINCT col1) FROM mytable
WHERE col4 = 'A'
GROUP BY col2;
统计col2为M的且保留col4均值>30以上的 col3和col4的均值
SELECT col3, AVG(col4) FROM mytable
WHERE col2 = 'M'
GROUP BY col3
WHERE AGV(col4) >30;
LIMIT
限制返回的行数。 可以有两个参数,第一个参数为起始行,从 0 开始;第二个参数为返回的总行数。 返回前5行
SELECT *
FROM mytable
LIMIT 5;
SELECT *
FROM mytable
LIMIT 0, 5;
返回3-5行
SELECT *
FROM mytable
LIMIT 3, 5;
排序
ASC & DESC
ORDER BY
SELECT col1, col2 FROM mytable ORDER BY col2 DESC
LIMIT 10;
去重
DISTINCT
相同值只会出现一次。 它作用于所有列,也就是说所有列的值都相同才算相同。
SELECT DISTINCT col1, col2
FROM mytable;
条件
CASE WHEN
SELECT id,
(CASE WHEN CAST(salary as float)<50000 THEN '0-5万'
WHEN CAST(salary as float)>=50000 and CAST(salary as float)<100000 THEN '5-10万'
WHEN CAST(salary as float) >=100000 and CAST(salary as float)<200000 THEN '10-20万'
WHEN CAST(salary as float)>200000 THEN '20万以上'
ELSE NULL END)
FROM table_1;
字符串
SUBSTR
CONCAT
返回顺序拼接的字符串
SELECT CONCAT('www','.baidu','.com') FROM mytable;
SPLIT
select sname from S where sno not in (
select sno from sc where cno in (select cno from c where cteacher ='liming')
)
select s.sname, sgrade from s join
(select sno from sc where scgrade <60 group by sno where count(*) >=2 ) s_1 on s.sno = s_1.sno
join (select sno, avg(scgrade) as sgrade from sc group by sno) s_2 on s_2.sno = s.sno
select sname from s where sno =
((select sno from sc where cno = 1) a join (select sno from sc where cno = 2) b on a.sno = b.sno
);